The Rise of Static Memory in LLMs
Separating Thinking from Remembering: A Survey of Memory-Augmented LLM Architectures
1 Background
1.1 The Need for Scale: Knowledge Primitives Limit Reasoning
Improving reasoning remains a primary goal for modern AI, yet recent findings (Zhang et al., 2025 [8]) highlight a critical bottleneck: a model’s reasoning potential is capped by the knowledge “primitives” absorbed during Pre-Training. While Post-Training can refine how a model thinks, it cannot fabricate knowledge from scratch; it merely optimizes the foundation laid earlier. Consequently, achieving substantial breakthroughs in reasoning requires massively scaling the pre-training stage to embed a far richer set of facts and primitives.
1.2 The Representation Reality: Computing vs. Retrieving
Standard Transformers face a major inefficiency when scaling knowledge. Interpretability research from Anthropic [7, 1] reveals that dense models do not store information in a static database; instead, they dynamically “compute” it. Retrieving a simple concept like “The Golden Gate Bridge” triggers a complex, expensive sequence of feature interactions across layers. This architecture conflates storage with processing, forcing the model to burn valuable computational resources (FLOPs) just to “remember” rather than to “think”.
2 Overview: PLE, STEM, Engram, LongCat
Modern LLMs traditionally conflate “reasoning” (dynamic computation) with “knowledge” (static fact retrieval). We use the same expensive matrix multiplications to calculate math problems as we do to recall that “Paris is the capital of France”.
Four emerging architectures—STEM (Meta/CMU) [6], PLE (Google DeepMind) [3], Engram (DeepSeek) [2], and LongCat (Meituan) [5]—address this by moving static information into Embedding Modules. Instead of computing facts, these models retrieve them. This shift decouples model capacity from inference cost, allowing for massive “memory” scaling without exploding GPU requirements.
| Feature | Gemma 3n PLE (DeepMind) | STEM (Meta/CMU) | Engram (DeepSeek) | LongCat (Meituan) |
|---|---|---|---|---|
| Date | June 26, 2025 | Jan 15, 2026 | Jan 12, 2026 | Jan 29, 2026 |
| Core Concept | Augmentation: Adds extra embeddings to modulate/augment layers. | Replacement: Swaps FFN Up-Projection for a Lookup Table. | Complement: Adds a “Memory Module” alongside the Neural Backbone. | Input Augmentation: Expands the model’s vocabulary/input capacity rather than depth. |
| Mechanism | Per-Layer Embeddings (Streamed) | Token-indexed Lookup (Static) | Hashed N-Gram Lookup (Contextual) | Input-Level N-Gram Lookup: Averages N-gram vectors into the input. |
| Hardware Goal | On-Device Efficiency (Low VRAM) | Training Stability & Interpretability | Massive Scaling (Memory vs. Logic) | Cache Efficiency: Uses “N-gram Caching” to bypass communication bottlenecks. |
| Key Win | Running 8B models on 3GB RAM phones | “Surgical” Knowledge Editing | +5.0 on Reasoning (BBH) by offloading facts | Pareto Efficiency: Beats parameter-equivalent MoEs on Coding & Agentic tasks. |
| Model Size | 2B (Effective 4B) | 1B (Evaluated at 350M & 1B) | 40B (Tested up to 100B Engram module) | 68.5B (~31B of which are static N-gram embeddings) |
3 Gemma 3n (Per Layer Embeddings)
3.1 The Architecture
Gemma 3n is engineered specifically for mobile/edge deployment [3]. Its goal is to fit a model with “8B parameter intelligence” onto a device that only has RAM for a 2B model.
- PLE (Per Layer Embeddings): Instead of storing all weights in the GPU/NPU memory (VRAM), it keeps massive embedding tables in the slower System RAM (CPU).
- Streaming: As the neural network processes layer \(i\), the specific embedding for that layer is streamed from the CPU to the NPU just in time.
- Mechanism: PLEs do not usually replace the FFN. Instead, they modulate the residual stream or the FFN output. The STEM paper notes that PLEs are often much lower dimension (e.g., 256 dim) compared to the model’s width.
3.2 Core Model Code
The Per-Layer Embedding (PLE) mechanism works by retrieving a massive, token-specific embedding vector that is pre-sliced to provide a unique “knowledge” input for every decoder layer [9]. As the model processes a token, each layer accesses its specific slice and dynamically gates it using the current hidden state—essentially using the active context to determine how much of the static retrieved knowledge to admit.
gemma3n/modeling_gemma3n.py
# The massive "Memory Bank" storing all layer-specific vectors for every token.
# Total Size: Vocab_PLE x (Num_Layers * PLE_Dim)
# Example Dimensions: 2M tokens x (40 layers * 256 dim)
self.embed_tokens_per_layer = Gemma3nTextScaledWordEmbedding(
config.vocab_size_per_layer_input,
config.num_hidden_layers * config.hidden_size_per_layer_input,
self.padding_idx,
embed_scale=config.hidden_size_per_layer_input**0.5,
)
def get_per_layer_inputs(self, input_ids: torch.LongTensor) -> torch.Tensor:
# Look up the massive vector and "slice" it for each layer.
# Input: [Batch, Seq_Len]
# Output: [Batch, Seq_Len, Num_Layers, PLE_Dim]
return self.embed_tokens_per_layer(input_ids).reshape(
*input_ids.shape,
self.config.num_hidden_layers,
self.hidden_size_per_layer_input,
)
# Inside the decoder loop, we pass the specific slice for this layer:
# per_layer_input = per_layer_inputs[:, :, layer_idx, :]
# Shape: [Batch, Seq_Len, PLE_Dim]
# ... inside the layer's forward pass ...
# A. GATE: Use the current context (hidden state) to determine "how much" memory to read.
# Project from Model_Dim (e.g., 2560) -> PLE_Dim (e.g., 256)
first_prediction = self.per_layer_input_gate(first_prediction)
first_prediction = self.act_fn(first_prediction)
# B. MODULATE: Inject the retrieved static memory via element-wise multiplication.
# Dynamic Context (Gate) * Static Memory (PLE Vector)
first_prediction = torch.multiply(first_prediction, per_layer_input)
# C. PROJECT: Mix the result back into the main residual stream.
# Project from PLE_Dim (e.g., 256) -> Model_Dim (e.g., 2560)
first_prediction = self.per_layer_projection(first_prediction)
first_prediction = self.post_per_layer_input_norm(first_prediction)
# D. ADD: Add to the model's prediction stream
corrected_predictions[1:] += first_prediction3.3 Key Findings
- VRAM Breakthrough: Allows running high-capacity models on phones with 3-4GB of RAM.
- Parameters vs. Compute: It massively increases the parameter count (knowledge capacity) without increasing the FLOPs (compute cost) or the active VRAM usage.
4 STEM (Scaling Transformers with Embedding Modules)
4.1 The Architecture
STEM [6] identifies that the Up-Projection matrix in a Feed-Forward Network (FFN) acts largely as a “Key” lookup in a Key-Value memory system.
- Change: It replaces the dense Up-Projection matrix (\(W^u\)) with a static, token-indexed embedding table (\(U_{token_id}\)).
- Retention: It keeps the Gate Projection (\(W^g\)) and Down Projection (\(W^d\)) as dense layers.
- Formula: \(y = W_{down}(\text{SiLU}(W_{gate}x) \odot \text{Lookup}(TokenID))\)
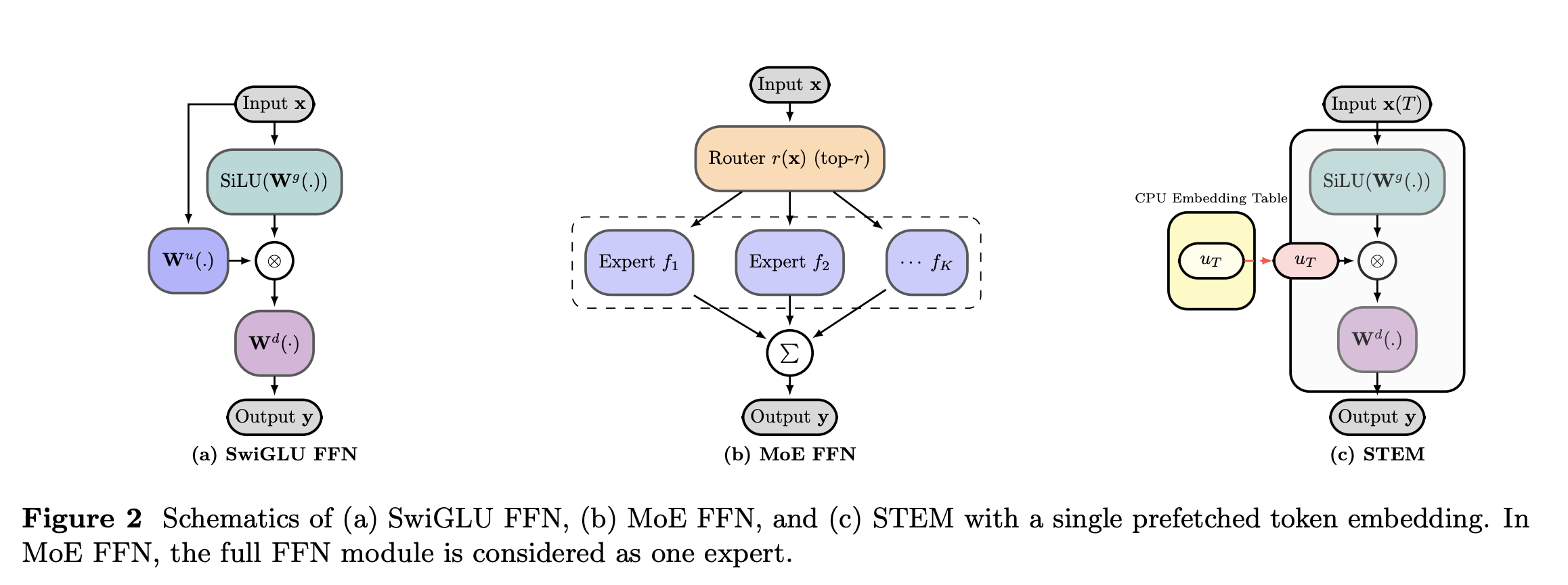 Figure: Schematics of (a) SwiGLU FFN, (b) MoE FFN, and (c) STEM.
Figure: Schematics of (a) SwiGLU FFN, (b) MoE FFN, and (c) STEM.
4.2 Core Model Code
The snippet below reflects the core logic [10].
lingua/stem.py
class STEMFFN(nn.Module):
def __init__(self, config):
super().__init__()
# 1. Gate Projection (W_g) - Kept Dense
# Determines "how much" of the knowledge to let through based on context.
self.gate_proj = nn.Linear(config.hidden_size, config.intermediate_size, bias=False)
# 2. Down Projection (W_d) - Kept Dense
# Projects the result back to the model's hidden dimension.
self.down_proj = nn.Linear(config.intermediate_size, config.hidden_size, bias=False)
# 3. STEM Embedding Table (U_l) - THE REPLACEMENT
# Replaces the dense "Up Projection" (W_u).
# Size: [Vocab Size x FFN Intermediate Size]
# This is the "Static Memory" containing layer-local facts for each token.
self.stem_embedding = nn.Embedding(config.vocab_size, config.intermediate_size)
self.act_fn = nn.SiLU()
def forward(self, x, input_ids):
# x shape: [Batch, Seq_Len, Hidden_Dim]
# input_ids shape: [Batch, Seq_Len]
# Step A: Compute the Gate (Contextual)
# Formula: SiLU(W_g * x)
# The gate looks at the *context* (x) to decide activation.
gate_output = self.act_fn(self.gate_proj(x))
# Step B: Retrieve Static Memory (Content)
# Formula: U_l[t]
# Instead of computing (W_u * x), we just look up the vector for the token.
# This vector represents the "fact" or "value" tied to this specific token in this layer.
stem_output = self.stem_embedding(input_ids)
# Step C: Combine (Gating)
# Formula: Gate * STEM_Embedding
# We multiply the static fact (stem_output) by the dynamic context (gate_output).
# If the gate is 0, the model ignores this fact for the current context.
activated_output = gate_output * stem_output
# Step D: Project Down
# Formula: W_d * (Activated_Output)
output = self.down_proj(activated_output)
return output4.3 Knowledge Specificity & Interpretability
The STEM embeddings are inherently linked to individual tokens. Viewing this through a memory lens, this embedding is intended to consolidate the essential information tied to its corresponding token. Consequently, these embeddings can potentially serve as steering vectors.
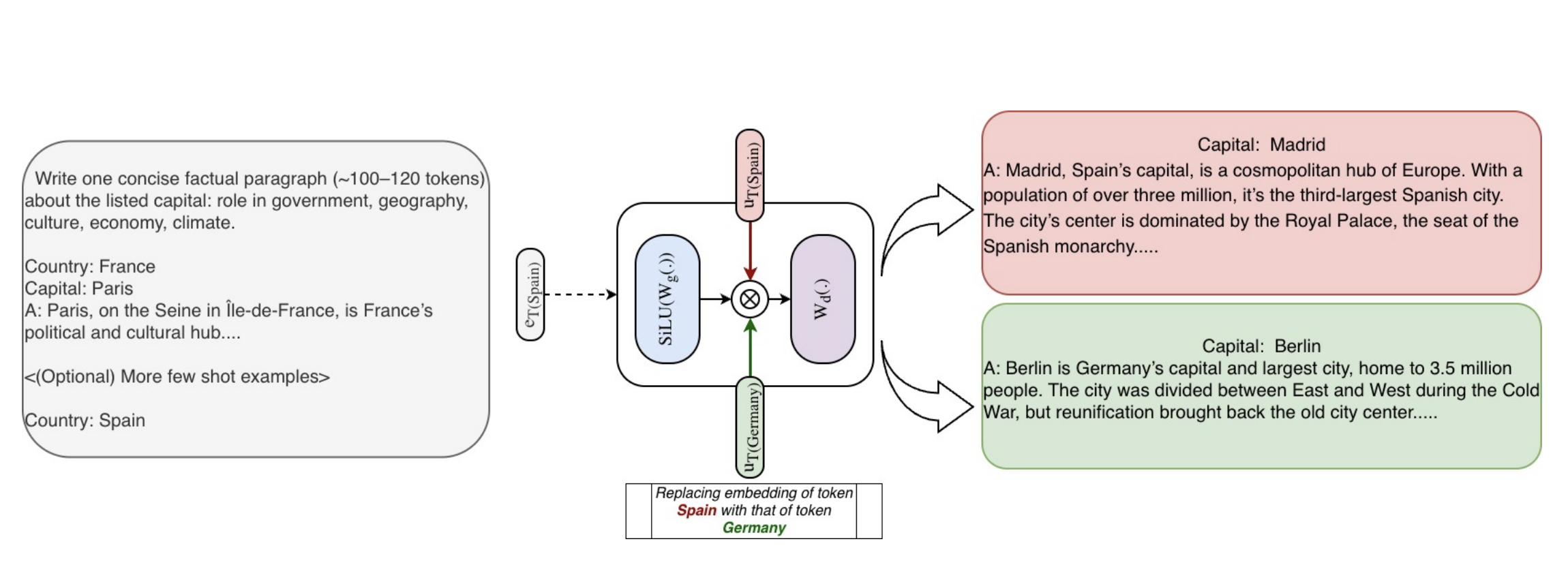 Figure: Knowledge injection/edit demonstration.
Figure: Knowledge injection/edit demonstration.
4.4 Key Findings
- Training Stability: Unlike Mixture-of-Experts (MoE), which suffers from load-balancing issues and loss spikes, STEM trains as stably as dense models.
- Efficiency: Removes ~1/3 of FFN parameters from the active compute path.
- Interpretability (The “Killer Feature”): Because embeddings are tied to specific tokens (e.g., “Spain”), researchers can perform Knowledge Editing. By swapping the “Spain” embedding for “Germany” in specific layers, the model can be tricked into “hallucinating” consistent facts (e.g., saying the capital of Spain is Berlin) without changing the input text.
5 Engram (DeepSeek)
5.1 The Architecture
DeepSeek introduces “Conditional Memory” [2] to address a fundamental inefficiency: while Transformers excel at reasoning (via Conditional Computation/MoE), they lack a native primitive for remembering, often wasting expensive compute to simulate knowledge retrieval.
- Engram Module: A dedicated module that augments the neural backbone, structurally separating the storage of static patterns from dynamic logic processing.
- Modernized N-Grams: Instead of standard single-token lookups, the model uses Hashed N-Grams to map multi-token sequences (e.g., “The capital of”) to static embedding vectors via fast, constant-time \(O(1)\) retrieval.
- Context-Aware Gating: The retrieved memory is fused intelligently, not blindly. A gating mechanism uses the model’s current hidden state to evaluate the static fact, integrating it only when relevant to the context while suppressing noise.
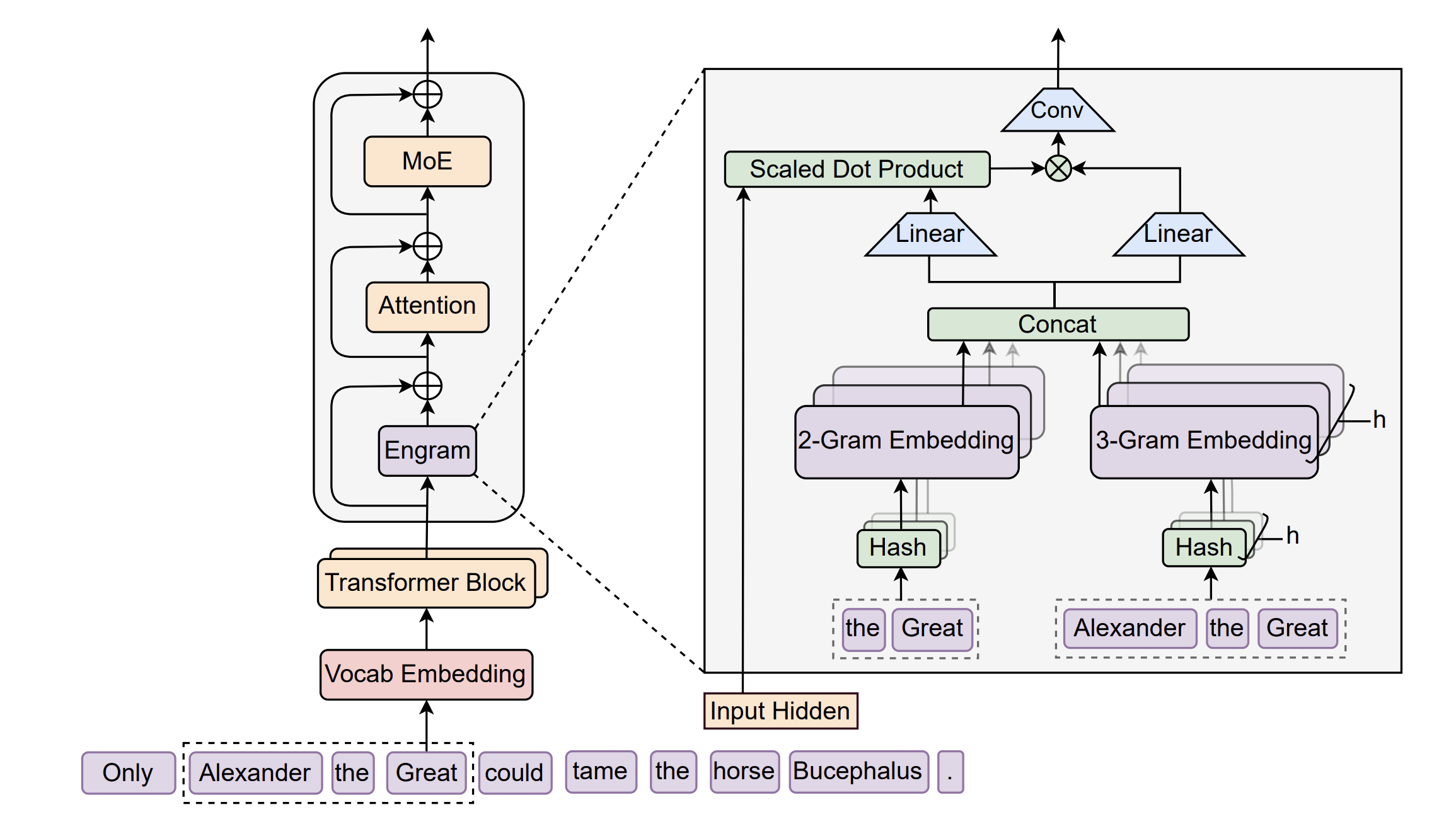 Figure: The Engram Architecture.
Figure: The Engram Architecture.
5.2 Key Findings
- The U-Shaped Scaling Law: DeepSeek found an optimal ratio between “Thinking Parameters” (MoE) and “Remembering Parameters” (Engram). Allocating ~20% of the parameter budget to Engram yields better results than a pure MoE model.
- Reasoning Gains: Surprisingly, offloading static knowledge to Engram improves reasoning benchmarks significantly. Engram-27B outperforms a parameter-equivalent MoE-27B baseline (e.g., BBH +5.0, MMLU +3.0, MATH +2.4). Why? By relieving the attention layers from the burden of “memorizing” facts, the model’s depth is freed up to perform complex logic.
- Needle-in-a-Haystack: Massive gains in long-context retrieval (84.2% -> 97.0%). The “local dependencies” are handled by the lookup table, leaving the attention mechanism free to scan the full global context.
- Zero-Cost “Infinite” Memory: Engram decouples model size from inference latency. Because the lookups are deterministic (based on N-grams), the system can prefetch embeddings from CPU memory (RAM) before the GPU needs them. Result: Offloading a massive 100B-parameter Engram table to host memory incurs a negligible throughput penalty (< 2.8%).
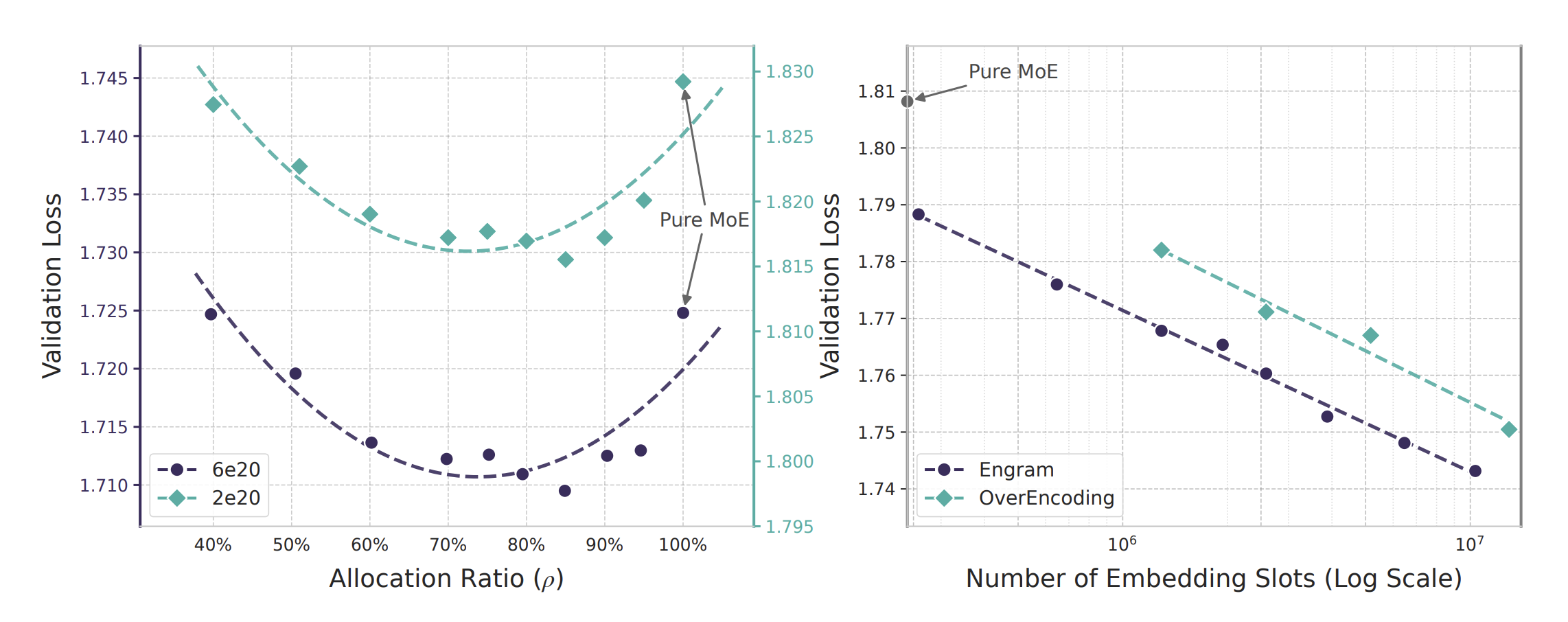 Figure: Sparsity allocation and Engram scaling.
Figure: Sparsity allocation and Engram scaling.
Unlike previous works that simply demonstrate that external memory improves performance, this paper provides a rigorous ablation study. Through their “Sparsity Allocation” experiments, the authors reveal a fundamental U-shaped scaling law: purely scaling experts (MoE) or purely scaling memory (Engram) is suboptimal. Instead, they identify a precise “sweet spot”—allocating ~20-25% of sparse parameters to static memory minimizes validation loss.
6 LongCat (Scaling Embeddings Outperforms Scaling Experts)
6.1 The Architecture
LongCat [5] challenges the dominant “Scaling Experts” (MoE) paradigm by proposing Embedding Scaling. Instead of adding more “brains” (experts) to the Feed-Forward Networks, it massively scales the Input Embedding Layer to capture rich local context.
- Input-Only Integration: Unlike STEM (which replaces FFNs) or Engram (which runs parallel to the backbone), LongCat adds N-gram embeddings only at the input level.
- Mechanism: The model retrieves massive N-gram vectors (2-grams, 3-grams) and averages them with the standard token embedding to create a “super-charged” input vector \(e_i\).
- Standard Backbone: The rest of the Transformer (Attention & FFNs) remains unchanged. It simply processes these denser, richer input vectors.
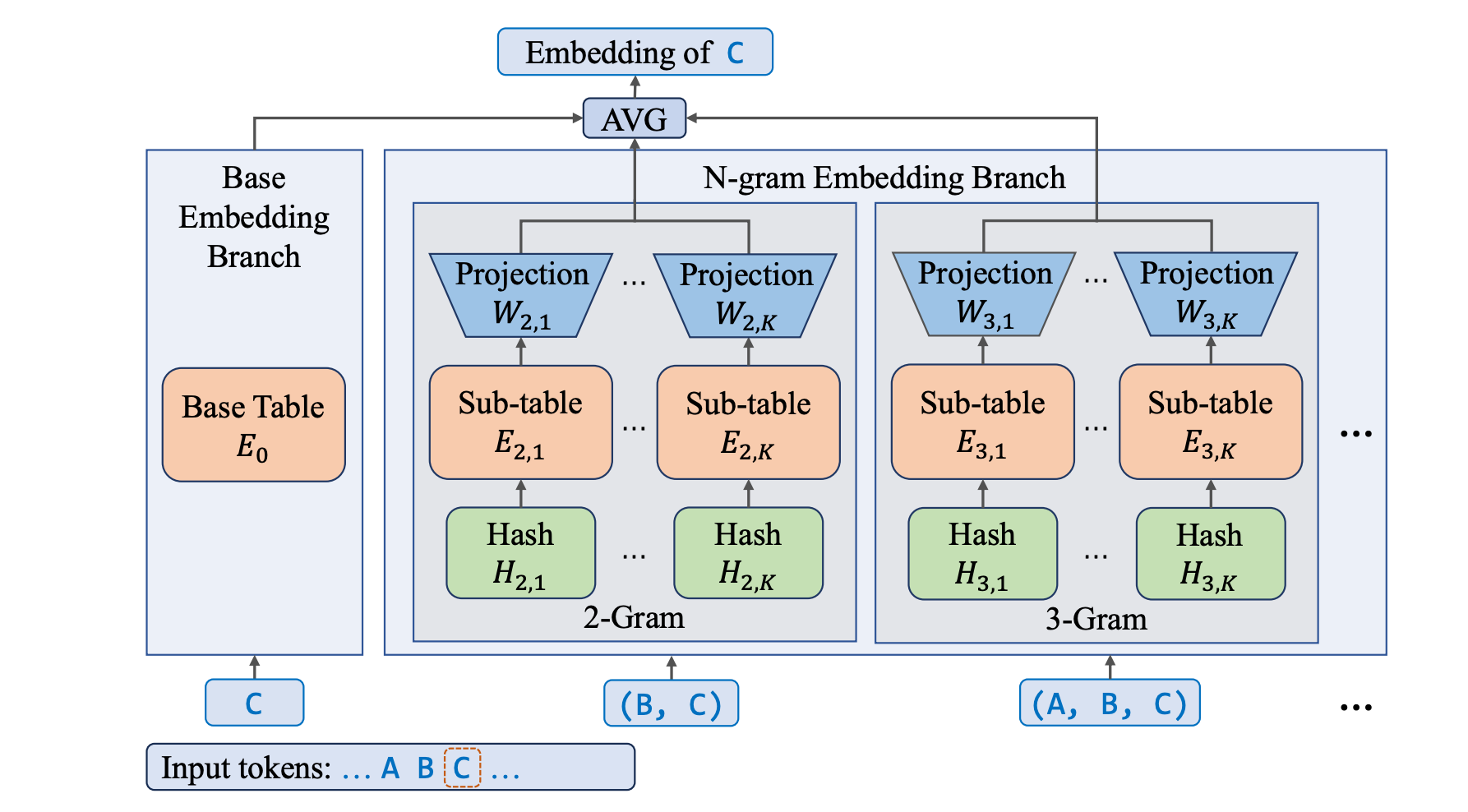 Figure: The architecture of a N-gram Embedding layer.
Figure: The architecture of a N-gram Embedding layer.
6.2 Key Findings
- The “Fat Embedding” Pareto Frontier: The authors found that once the number of experts reaches a certain point, adding more memory (embeddings) yields better returns than adding more experts.
- The 50% Allocation Rule: The optimal design allocates roughly 50% of the total parameter budget to these static embeddings. Example: LongCat-Flash-Lite is a 68.5B parameter model, but ~31.4B parameters are just the embedding table.
- Wide vs. Deep: This method works best in wider models. In very deep models, the signal from the input embeddings tends to fade (“wash out”) as it propagates through many layers.
- Performance: The 68.5B model (with only ~3B active params) outperformed parameter-equivalent MoE baselines, showing particular strength in coding and agentic tasks where local context is critical.
References
- Ameisen, E. et al. (2025). Circuit Tracing: Revealing Computational Graphs in Language Models. Anthropic.
- Cheng, X. et al. (2026). Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models. arXiv:2601.07372
- Google DeepMind (2025). Gemma 3 Technical Report. arXiv:2503.19786. Model card: Gemma 3n.
- Lindsey, J. et al. (2025). On the Biology of a Large Language Model. Anthropic.
- LongCat (2026). Scaling Embeddings Outperforms Scaling Experts in Language Models. arXiv:2601.21204
- Sadhukhan, R. et al. (2026). STEM: Scaling Transformers with Embedding Modules. arXiv:2601.10639
- Templeton, A. et al. (2024). Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet. Anthropic.
- Zhang, J. et al. (2025). On the Interplay of Pre-Training, Mid-Training, and RL on Reasoning Language Models. arXiv:2512.07783
- Google DeepMind. Gemma 3n model code.
gemma3n/modeling_gemma3n.py. - Lingua / STEM. STEM model code.
lingua/stem.py.