Deep dives into LLM architecture, post-training, and the bridge between research and production.
Why on-policy self-distillation is a natural complement to standard RL, and how SDPO, OPSD, and GLM-5 implement it.
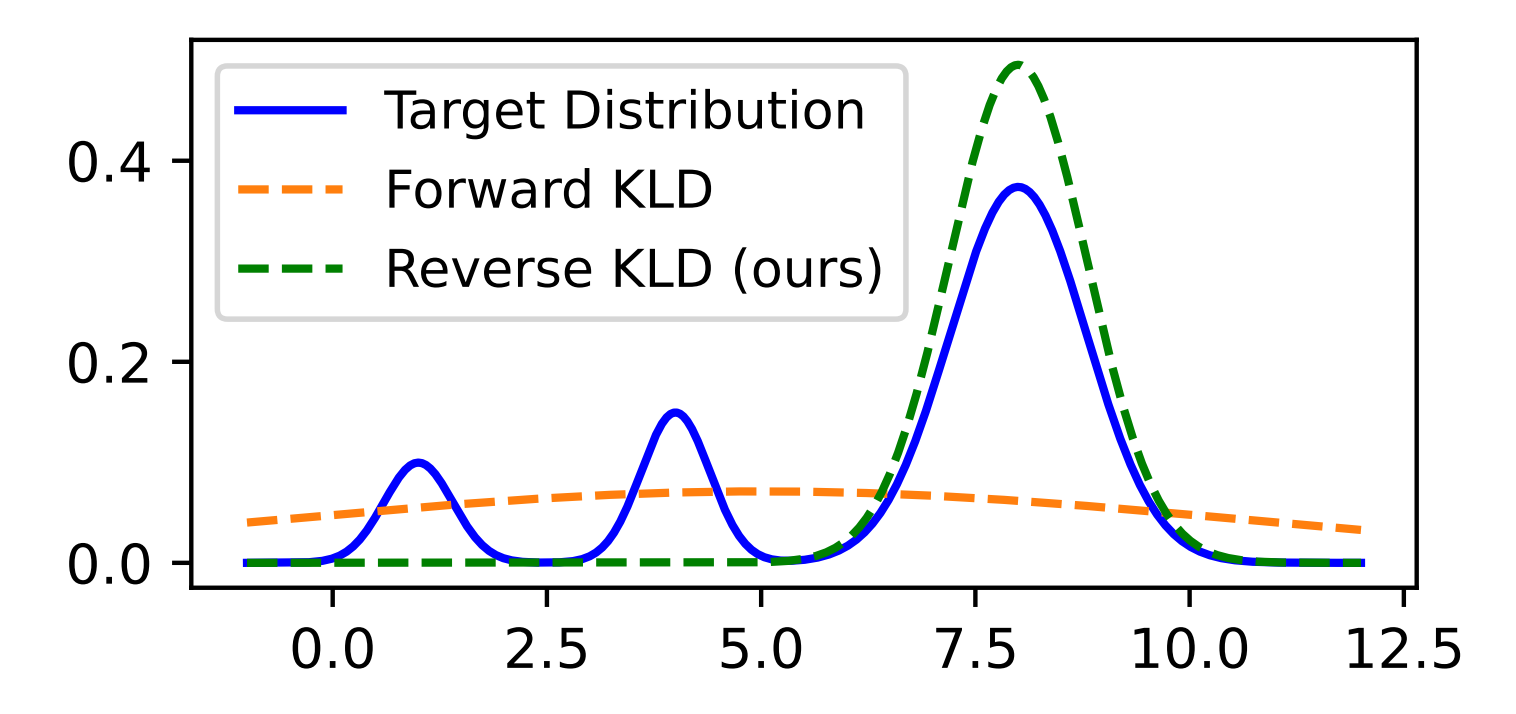
Why standard SFT causes catastrophic forgetting, and how contextual on-policy self-distillation fixes it from first principles.
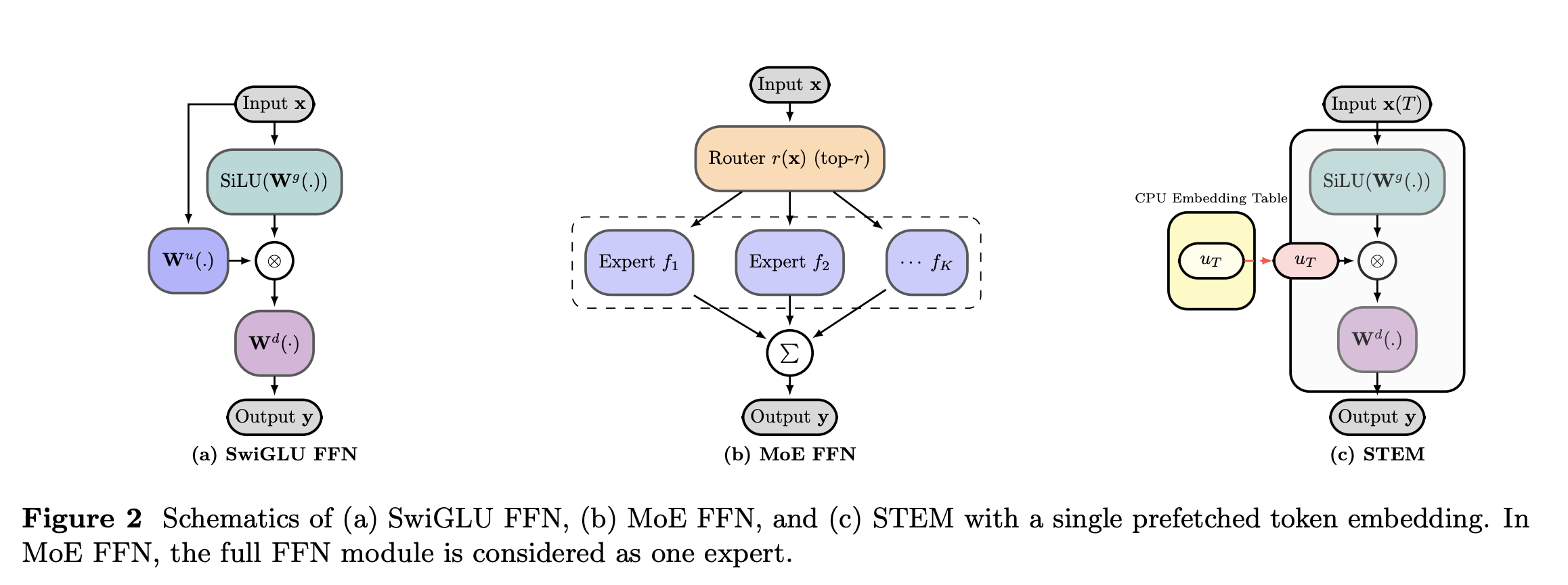
How PLE, STEM, Engram, and LongCat decouple knowledge storage from reasoning by moving static facts into embedding modules.